STAR
STAR: Speech-to-Audio Generation via Representation Learning
| Paper | Youtube Demo | HuggingFace Space | Code |
|
Abstract.
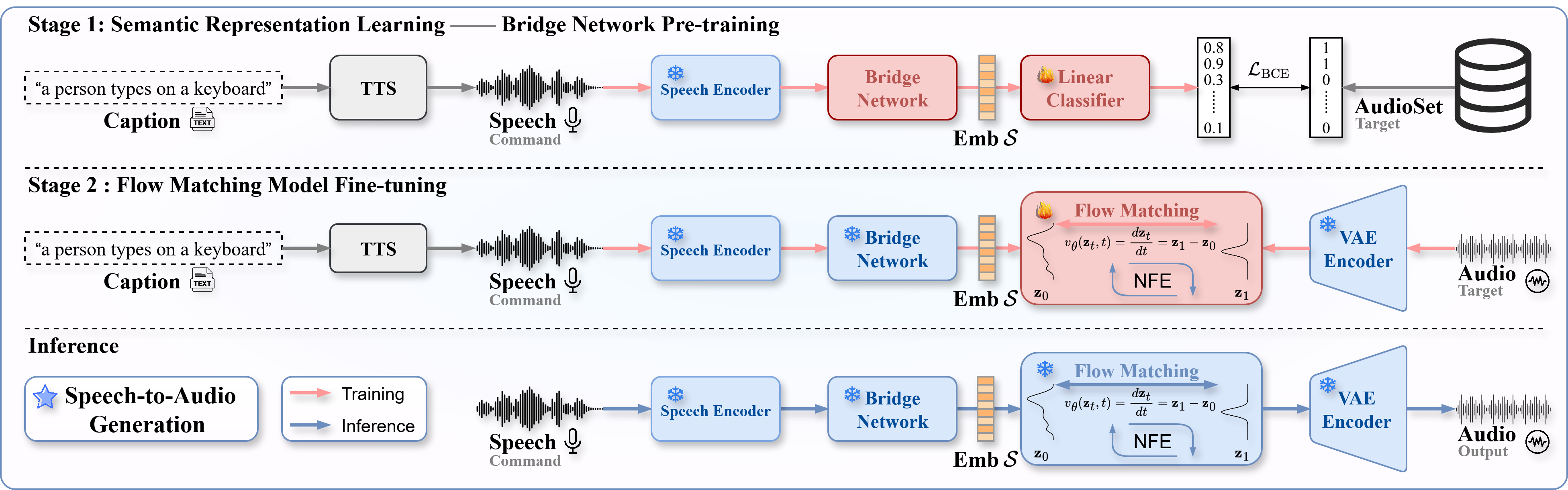
This work presents STAR, the first end-to-end speech-to-audio generation framework, designed to enhance efficiency and address error propagation inherent in cascaded systems. Unlike prior approaches relying on text or vision, STAR leverages speech as it constitutes a natural modality for interaction. As an initial step to validate the feasibility of the system, we demonstrate through representation learning experiments that spoken sound event semantics can be effectively extracted from raw speech, capturing both auditory events and scene cues. Leveraging the semantic representations, STAR incorporates a bridge network for representation mapping and a two-stage training strategy to achieve end-to-end synthesis. With a 76.9% reduction in speech processing latency, STAR demonstrates superior generation performance over the cascaded systems. Overall, STAR establishes speech as a direct interaction signal for audio generation, thereby bridging representation learning and multimodal synthesis. Generated samples are available below. Demo Navigation.