SARA Construction
Pipeline
An overview of the SARA autoencoder training, text-to-latent DiT training, and inference pipeline.
Blue arrow
SARA training: the input audio is fed into SARA semantic encoder to extract semantic latents, which serve as conditions to train SARA flow-matching-based deocder for latent-to-waveform prediction.
Red arrow
Generative audio DiT training: the input text is processed by a text encoder to obtain textual features, which are used to train the DiT model for text-to-semantic-latents generating.
Black arrow
Downstream task inference: equipped with SARA, both audio generation and understanding tasks can be performed within the same semantic latent space.
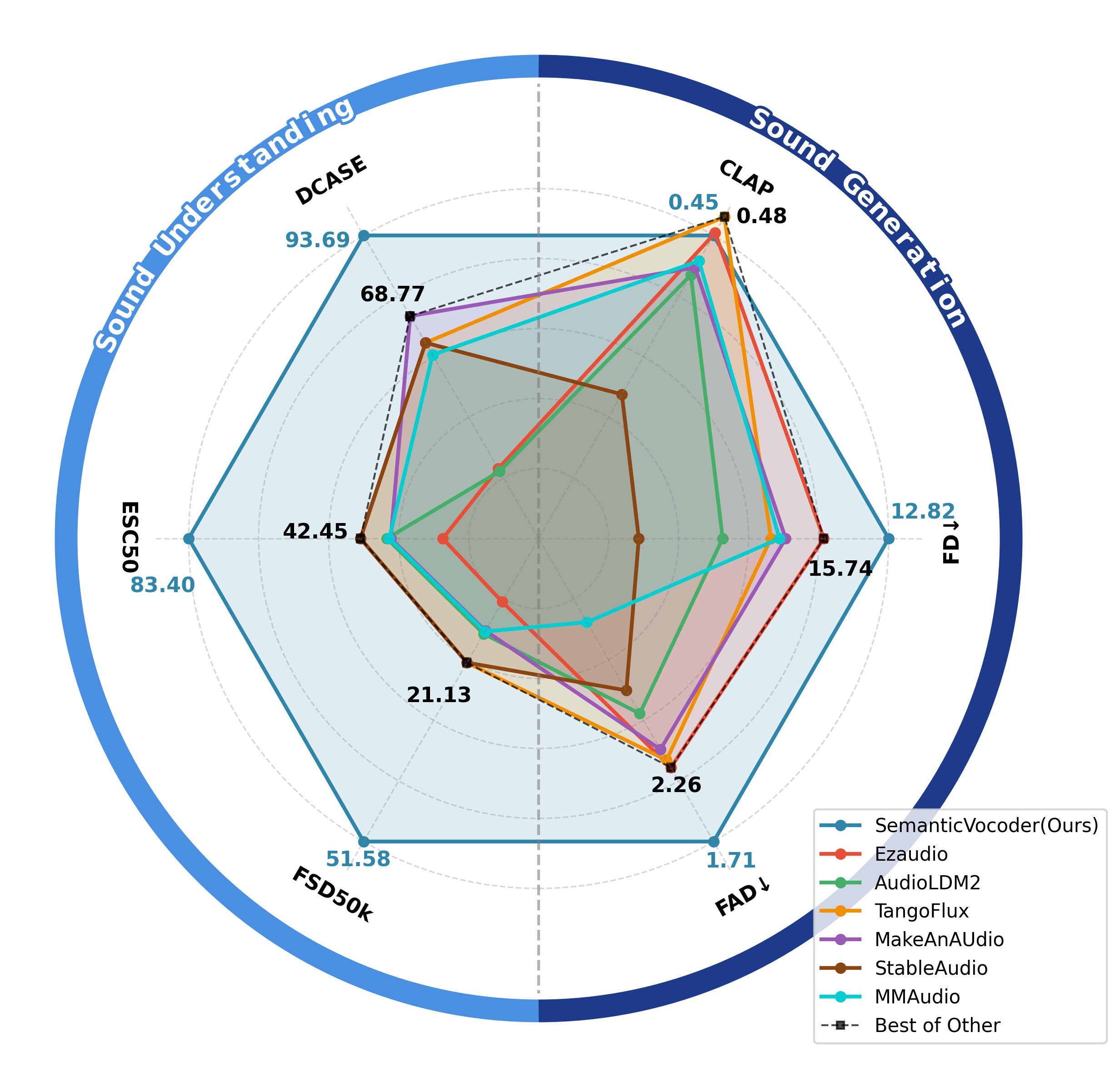
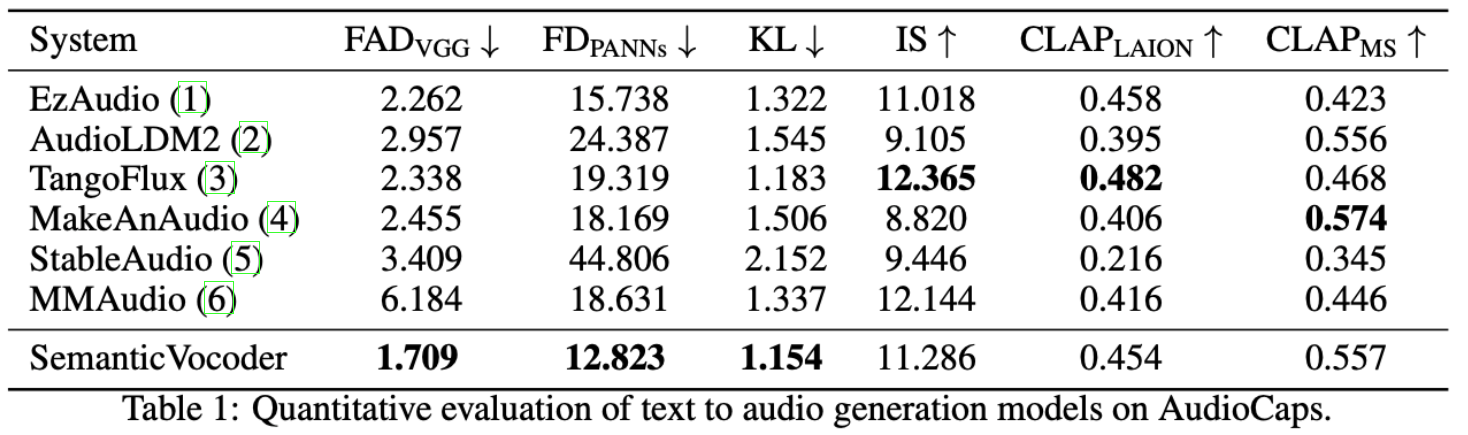
Comparison
The SARA pioneers the generation of waveforms directly from semantic latents, thereby bridging understanding-oriented representations and generation tasks.
Left
Three sub-tasks from the HEAR benchmark are employed to evaluate the latent representations, in which linear classifiers are trained on fixed latents.
The semantic latents exhibit a more discriminative semantic structure than the acoustic VAE latents used in previous work.
Right
For the downstream text-to-audio task, a text-to-latent model predicts latents conditioned on input text.
The predicted latents are then fed into SARA for audio synthesis, yielding superior performance.
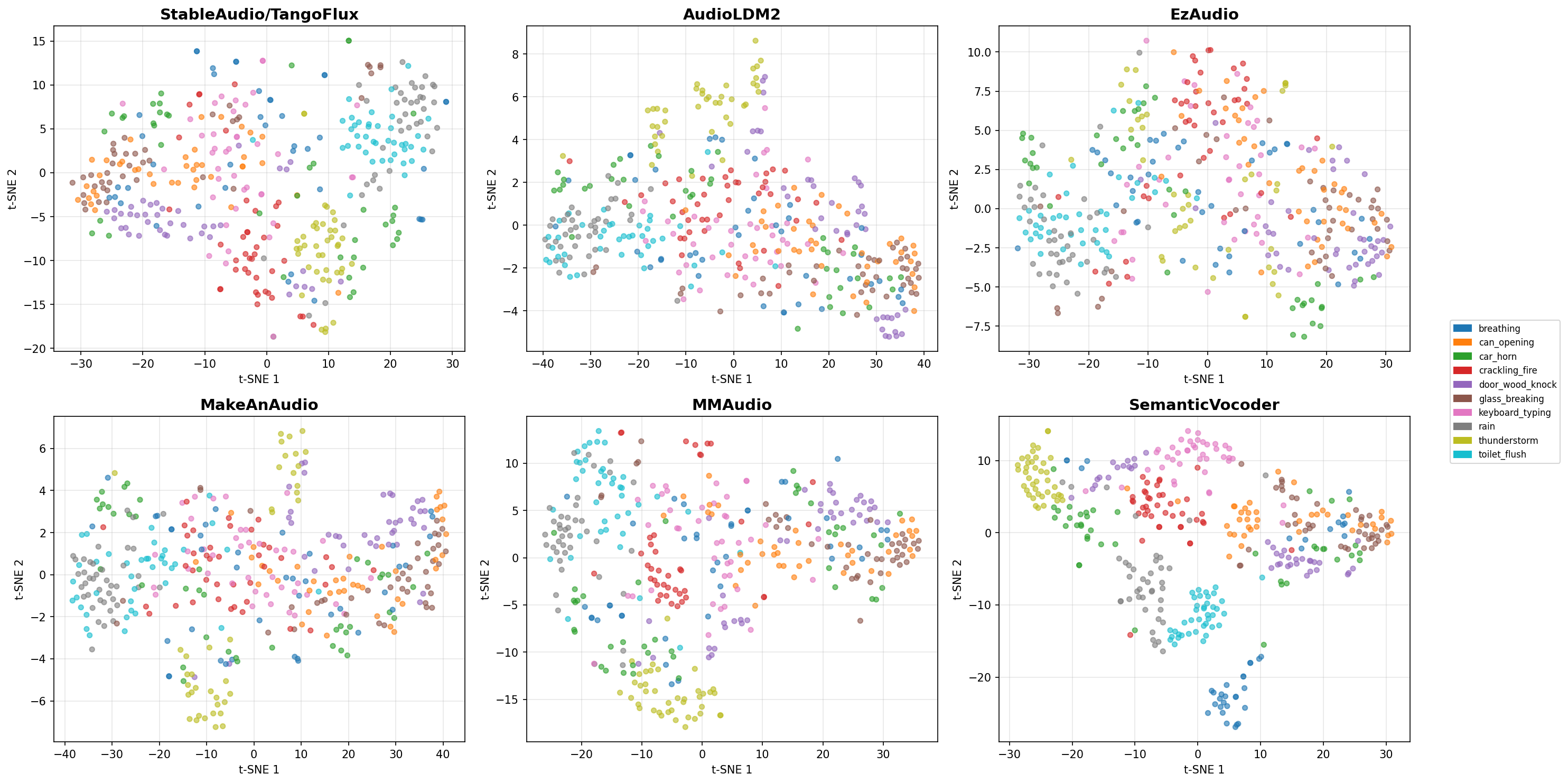
Visualization of different latents on HEAR-ESC50, where the 10 most frequent categories are presented. Each audio feature is aggregated by mean pooling along the temporal axis and projected into 2D space via t-SNE. Compared to VAE acoustic latents used in baseline models, semantic latents exhibit a more discriminative structure and superior semantic disentanglement.
Visualization
Visualization of different latents on HEAR-ESC50, where the 10 most frequent categories are presented. Each audio feature is aggregated by mean pooling along the temporal axis and projected into 2D space via t-SNE. Compared to VAE acoustic latents used in baseline models, semantic latents exhibit a more discriminative structure and superior semantic disentanglement.